지난 Datasync 구축 글에 이어서 이번엔 storage gateway를 끼얹어보겠다.
https://raid-1.tistory.com/192
목표 : 온프레미스 스토리지와 aws클라우드상 S3 버킷의 실시간 데이터 싱크
방식 : AWS DataSync를 사용하여 온프레미스 NFS 서버에서 Amazon S3로 데이터를 마이그레이션하고
AWS Storage Gateway를 사용하여 S3에 있는 데이터를 온프레미스에서 NFS 액세스하여 사용.
이번엔 S3 버킷에 연결하도록 온프레미스 파일 게이트웨이를 구성한뒤
NFS를 통해 클라우드 내 파일에 대한 액세스를 할것이다.

공식 aws storage gateway 구성 설명 문서
https://docs.aws.amazon.com/storagegateway/latest/vgw/GettingStarted.html
이 부분은 아주 중요하다. 파일 게이트웨이에 필요한 네트워크 조건들을 소개하고 있는 문서다.
눈여겨 볼 것은 포트. 이것에 맞게 시큐리티 그룹이나 방화벽을 열어야 한다.
https://docs.amazonaws.cn/en_us/filegateway/latest/files3/Requirements.html
아래 포트를 열어준다. (인바운드는 * 표)
TCP 80*,22
TCP 1026~1028
TCP 1031
TCP 443 = https
UDP123 = NTP
TCP/UDP 53 = DNS
TCP/UDP 111* = NFSv3
TCP/UDP 20048* = NFSv3
TCP/UDP 2049* = NFS
1. File Gateway 생성

Datasync때도 배포해줬던 Agent ova파일 같은게 또 있다.
이걸 VMware 머신에 추가해준다.

이번에도 ID는 admin 이고 비번은 password가 디폴트다.
192.168.108.131 할당받은걸 보니 저번 datasync와 같은 문제는 일어나지 않은걸로 보인다.
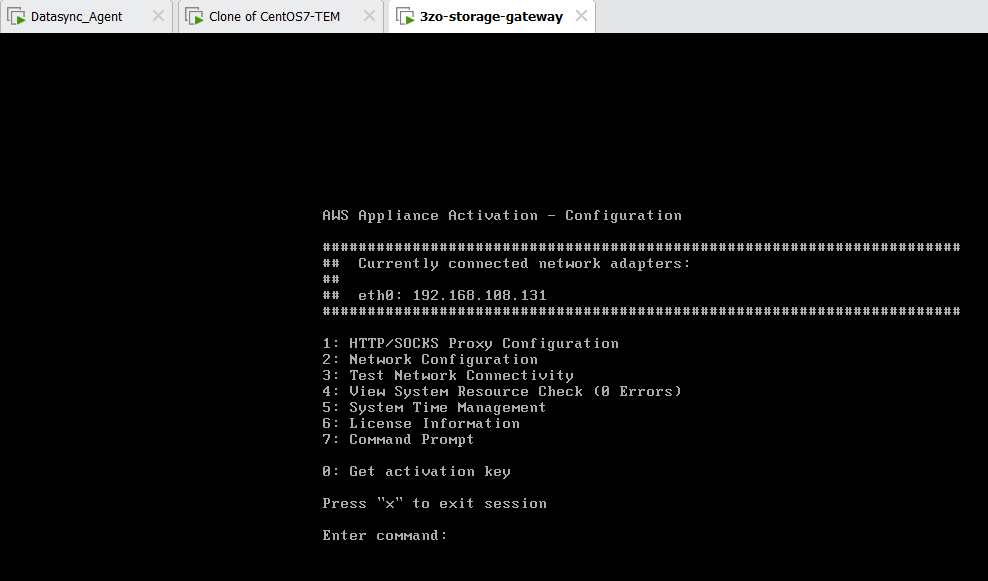
만약 이 화면에서 ip를 잘 안받아오면 아래 DHCP 서비스를 켜주면 받아오기도 하더라.
(근데 체크 안돼있는데도 잘 작동하긴 해서 필수는 아닌듯)

NTP 시간 동기화 해달라고 써있으니까 5번 누르고 2번 눌러서 아래 NTP 서버중 한곳 추가해주자.
2번 말고도 1번 누르면 알아서 아마존 NTP랑 동기화 해준다.


아니 갑자기 에이전트가 멋대로 재시작하는 바람에 3단계 검토단계에서 다음으로 안넘어가졌다.
깜짝이야.
재시작 하고나면 넘어가진다.

캐시 스토리지(cache storage) 할당
게이트웨이는 캐시 스토리지를 사용하여 최근에 액세스한 데이터에 짧은 대기 시간 액세스를 제공합니다. 캐시 스토리지는 업로드 버퍼에서 Amazon S3로의 업로드를 보류 중인 데이터에 대한 온프레미스 내구성 저장소 역할을 합니다. 일반적으로 캐시 스토리지 크기는 업로드 버퍼 크기의 1.1배입니다.
음...agent 머신에 디스크를 하나 꼽아줘야하겠다.


권장이 150G 실환가.. 개인 PC로는 무리니까 그냥 8G 주겠다.

CloudWatch 로그 그룹 패널 에서 로깅 비활성화를 선택 하고 그대로 구성을 클릭한다.
어라 나중에 온프레미스 VMware에 HA 구성할수도 있는데 그럴 경우는 여기 설정을 또 만져야 될수도 있겠다.


2. Storage Gateway NFS 공유 생성
여기까지 아까 만든 게이트웨이랑 Datasync 했던 S3버킷 골라주고 아래 하얀 버튼을 눌러준다.
'구성 사용자 지정'

여기서 세부 설정이 가능하다.


2단계는 그냥 디폴트로 놔두고 다음을 누른다.

클라이언트 추가를 누른다.
아마 추가버튼이 계속 있는 것으로 보아 여러 객체를 스토리지 게이트웨이에 엑세스 시킬수 있나보다.
에이전트도 여러개여야 하겠지만?
에이전트의 사설 IP 주소를 추가하고 "/32"를 추가한다.
이렇게 하면 응용 프로그램 서버만 게이트웨이의 NFS 파일 공유에 액세스할 수 있기 때문이다.


파일 메타데이터는 기본으로 두고 다음을 누른다.
다 만들어지면 아래와 같은 파일공유 템플릿이 있는데, 눌러보면 아래와 같이 마운트 명령어를 예제로 준다.
이를 기억해 두자.

3. 애플리케이션 서버에 NFS 공유 마운트
이제 어플리케이션 서버에서 직접 File Gateway로 마운트 해야한다.
이전 Datasync 구축 게시글에서 한 작업으로
에플리케이션 서버 (nfs-client) 192.168.108.5 는 nfs-server 192.168.108.3에 nfs 마운트가 이미 돼있는 상태다.

그다음 File gateway에 또 마운트를 할 디렉터리를 만들어주자.

아까 스토리지 게이트웨이 파일공유 템플릿에서 리눅스 마운트 명령어를 복사해다가
[MountPath]"를 "/fgw"로 바꿔서 어플서버에 입력해주면 된다.

mount -t nfs -o nolock,hard 192.168.108.131:/3zo-fileshare-storagegateway-temp /fgw
아 이번엔 여기서 부터 트러블 슈팅이구나.
잘 안된다.

4. 트러블슈팅
클라이언트에 NFS 파일 공유 마운트
https://docs.aws.amazon.com/filegateway/latest/files3/GettingStartedAccessFileShare.html
NFS 클라이언트에 Storage Gateway NFS 파일 공유를 탑재할 수 없는 경우 문제를 해결하려면 어떻게 해야 합니까?
https://aws.amazon.com/ko/premiumsupport/knowledge-center/storage-gateway-troubleshoot-nfs-mount/
요 문서 보고 5번까지 따라하고 해결이 됐다.
일단 의심되는 당첨 해결방법
1. 어플리케이션 서버에 다시 nfs-utills를 설치
yum -y install nfs-utils
2. firewalld 끄기
(아니면 포트번호 2049, 111,20048 오픈)
3. 파일공유에 허용된 클라이언트 목록에 어플리케이션 서버 ip 추가.

이부분이 이해는 안가지만 일단 사설망 뒷단에 있는 어플리케이션 서버의 ip도 추가해줬다.
중간의 파일게이트웨이를 통해서 클라우드와 어플리케이션 서버가 통신하는것 아닌가?
그럼 왜 클라우드단에서 사설 내부의 어플리케이션의 ip를 허용해줘야하는걸까.
애초 마운트 명령어에 클라우드의 DNS 이름이 들어가 있을 때 부터 의문이긴 했다.
아무튼 파일게이트웨이ip 아래에 어플리케이션 서버ip도 추가해줬다.

마운트 성공!

이제 어플리케이션 서버는 토폴로지대로 2개의 마운트 지점을 갖게된다.


5.검증
명령어 실행하여 두 NFS 공유에 동일한 파일 집합이 있는지 확인해보겠다.
/fgw: .aws-datasync-metadata에 하나의 추가 파일만 표시되어야 한다.
이 파일은 작업이 실행될 때 S3 버킷의 DataSync에 의해 생성된 것이다.
다른 모든 파일은 동일하며 데이터가 오류 없이 DataSync에 의해 완전히 전송되었음을 나타낸다.
diff -qr /nfs-cli /fgw

어플리케이션 서버에서 /fgw에 이전 Datasync했던 내용물이 들어와있다.

어플리케이션 서버에서 /fgw에 hohoharin 파일을 만들어준다


S3버킷으로 직행했다.
둘이 생성 시간을 비교해봐도 거의 동시에 업로드 된 것을 확인할 수 있다.

반대로 클라우드 S3버킷에 zozo3zo 파일을 업로드한뒤
어플리케이션 서버에서 확인해본다.


성공성공~~~
이거 해서 단점이 있다면
AWS - > IDC로 데이터가 전달(캐싱) 되는건 수동으로 캐시 새로고침 하거나 자동 (최소5분) 으로 옵션골라야한다.
.....5분의 텀이 있는건좀..
그래서 다들 API 에 코딩해서 실시간동기화 한다는데 그건 다음번에 하겠다.

서버가 먼저 켜져있어야 클라이언트가 제대로 마운팅된다. 부팅순서가 중요해진다.
그리고 단점이 또있다면
파일게이트웨이에 달아준 하드는 저장하는 스토리지가 아니라 캐싱스토리지인걸 보면 알겠지만, 캐싱역할만한다.
이게 무슨의미냐면, aws와 연결이 끊기면 내 서버에서 내용물을 못열어본단소리다.
그래서 지속적으로 해당 캐싱스토리지를 rsync로 다른 저장소에 백업한뒤 그 저장소를 어플리케이션 서버가 갖다 쓰는 구조가 이상적이다.
그리고 아직은 자동 캐싱리프레시(cheching refresh) 최소 예약 단위가 5분이라 5분간의 RPO상의 로스가 발생한다.
Rsync와 inotifywait를 사용한 백업을 다음 게시글에서 구축해줬다.
https://raid-1.tistory.com/210
그리고 자동 캐싱리프레시(cheching refresh) 최소 예약 단위가 5분인 단점을 해결하기 위해
찾아본 결과 스토리지게이트웨이랑 비슷한 작동을 하면서 실시간으로 싱크해주는 프로그램을 찾았다.
이 경우에는 API상으로 통신하기때문에 인터넷통신이라고한다.
다음엔 이것으로 개인프로젝트를 해보려고 한다.
'AWS' 카테고리의 다른 글
| [Project] Openswan을 이용한 VPN site-to-site (0) | 2023.03.06 |
|---|---|
| [Project] - Datasync + storage gateway로 실시간 싱크-3 (0) | 2023.03.06 |
| [Project] - Datasync + storage gateway로 실시간 싱크-1 (0) | 2023.03.02 |
| [project] DB DMS 실시간 동기화 (온프레미스 DB와) (0) | 2023.02.27 |
| [클라우드 보안] WAF DVWA 미니프로젝트 -하편- (0) | 2023.02.21 |


