awk
문자데이터는 기본적으로 행 정보만 있고 열 정보는 없다.
하지만 awk는 열 정보를 이용한 필터링이 가능하다.
매뉴얼
man awk
설명란 맨 앞줄부터 본인은 프로그래밍 언어라고 자칭하고있다.
그만큼 잘 만든 명령어라는 자부심이 느껴진다.

awk 시스템 변수
awk가 내부적으로 인식하는 변수들이다. 이것을 이용하면 조금 더 효율적으로 사용 할 수 있다.
많은 부분에서 엑셀이 생각나는 명령어다.
변수명 내용
------------------------------------
FILENAME 현재 처리중인 파일명
FS 필드(열) 구분자로 디폴트는 공백
RS 레코드(행) 구분자로 디폴트는 새로운 라인
NF 현재 레코드의 필드 개수
NR 현재 레코드의 번호
OFS 출력할 때 사용하는 FS
ORS 출력할 때 사용하는 RS
$0 입력 레코드의 전체
$n 입력 레코드의 n번째 필드
awk 비교 Operator
=================================================================
< Less than.
<= Less than or equal.
== Equal.
!= Not equal.
>= Greater than or equal.
> Greater than.
~ Contains (for strings)
!~ Does not contain (strings)
awk 산술 Operator
=================================================================
+ plus
- minus
* multiply
/ divide
% module
** power
연속 처리 연산자
=================================================================
&& and 연산자 (참참)
|| or 연산자 (참참, 참거짓, 거짓참)
Assignment
더하기의 결과를 대입
a += 10
d += c
a = a + 10
a = a + c
-=
빼기의 결과를 대입
a -= 10
d -= c
a = a - 10
a = a - c
*= 곱하기의 결과를 대입
a *= 10
d *= c
a = a * 10
a = a * c
%= 나머지의 결과를 대입
a %= 10
d %= c
a = a % 10
a = a % c
준비물
cat << EOF > example.txt
1 share 5 20.00
2 compressional 10 2.00
3 anisotropy 30 3.50
4 perovskite 2 45.50
5 olivine 25 33.19
EOF
모든 필드 출력
현재 공백 기준으로 필드가 나뉘어 있는 디폴트 설정을 받는다.
cat example.txt | awk '{print $0}'

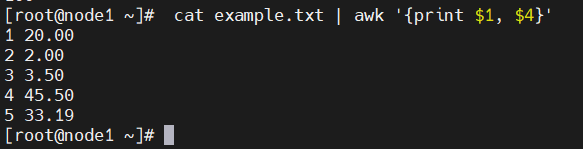
1번째 4번째 필드의 내용을 출력
cat example.txt | awk '{print $1, $4}'
-F 옵션 (필드)
필드(열) 를 구분하기 위해 쓰는 옵션이다.
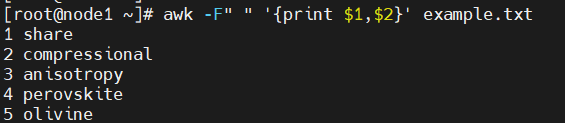
일치하는 열의 데이터만 출력
" "는 필드 구분자(FS)가 공백이라는 뜻이다
(사실 디폴트가 공백이라 안바꿨으면 안써도 되는 상황)
awk -F" " '{print $1,$2}' example.txt
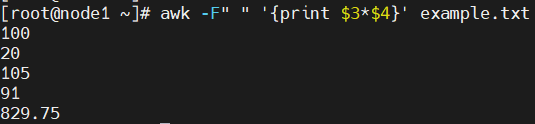
전체 레코드에서 3번째와 4번째 필드의 곱 출력
awk -F" " '{print $3*$4}' example.txt
share와 매칭되는 레코드에서 3번째와 4번째 필드의 곱 출력
awk -F" " '/share/ {print ($3*$4)}' example.txt

특정 열에 share가 매칭되면 필드 3과 필드 4를 곱하여 출력
~ Contains (for strings)
!~ Does not contain (strings)
필드1에는 share가 없어서 결과 값이 없다.
awk -F" " '$1 ~ /share/ {print $3*$4}' example.txt
필드2에는 share가 있어서 결과 값이 출력 된다.
awk -F" " '$2 ~ /share/ {print $3*$4}' example.txt

조건문
| awk | 옵션 | BEGIN{ } | { } | END{ } |
| 변.선 | 처리 | out | ||
| (BEGIN과 END는 생략 가능. 처리 부분만 존재하면 됨) | ||||
모든 레코드(행) 중 레코드 번호가 3보다 큰 행만 출력
아래와 같이 12345 레코드중 45만 출력됐다.
NR 현재 레코드의 번호
awk 'NR > 3 {print $0}' example.txt

이렇게 표시되는 값에 "주석"을 더해서 출력되게 할 수도 있다.
awk 'NR > 3 {print "Total lines: " $0}' example.txt

3번째 필드 값이 20보다 큰 행만 "주석"을 달아서 출력한다.
awk '$3 > 20 {print "Total lines: " $0}' example.txt

레코드 번호가 2보다 크고 5보다 작은 행 출력
# awk 'NR > 2 && NR < 5 {print $0}' example.txt

레코드 번호가 2보다 작은 행, 5보다 큰 행 출력
awk 'NR < 2 || NR > 4 {print $0}' example.txt

모든 레코드 중에 레코드 번호가 2보다 큰 행이고 필드 2가 olivine인 행 출력
awk 'NR > 2 && $2 ~ /olivine/ {print $0}' example.txt

END 필드 입력
모든 레코드중에 마지막 레코드(행)가 출력된다.
awk 'END {print $0}' example.txt

레코드 번호중에 마지막 것이 출력 된다.
awk 'END {print NR}' example.txt

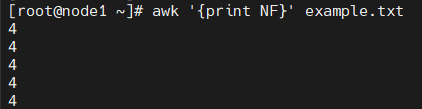
모든 레코드의 필드 개수가 출력된다.
awk '{print NF}' example.txt
필드 개수 중에 마지막 것이 출력된다.
NF 현재 레코드의 필드 개수
awk 'END {print NF}' example.txt

BEGIN 필드 입력
필드 구분자 ‘#’ 를 적용하여 출력한다.
OFS 출력할 때 사용하는 FS
FS 필드(열) 구분자로 디폴트는 공백
awk 'BEGIN {OFS="#"} {print $1,$2}' example.txt

awk 'BEGIN {OFS="#"} {print $1,$2,$3}' example.txt

※ 주의 : FS는 출력할때 쓰는게 아니라 입력할때 인식하는 옵션이므로
없는 FS를 BEGIN 값에 주면 구분자 인식을 못 해서 전체를 출력 해줌
awk 'BEGIN {FS="#"} {print $1,$2}' example.txt

FS 구분자를 주고 출력 구분자를 ‘#’로 설정
사실 디폴트 FS가 공백이라 드라마틱한 결과는 안나온다.
awk 'BEGIN {FS=" ";OFS="#"} {print $1,$2}' example.txt

bigin, end 연산자를 사용하여 출력
awk 'BEGIN {FS=" ";OFS="#";print "+++++++++"} {print $1,$2} END {print "==========="}' example.txt

대입 연산자 활용
# awk 'BEGIN {x=1} {print $0,x++}' example.txt
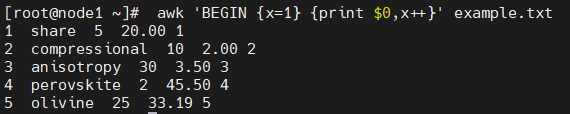
# awk 'BEGIN {x=1} {print $0,x--}' example.txt
# awk 'BEGIN {x=1} {print $0,x+=10}' example.txt
실제 적용
준비물
cp -v /etc/passwd ./

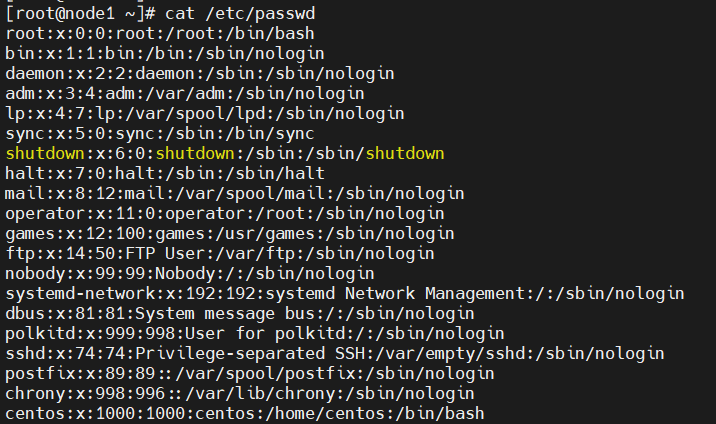
1번째 필드와 7번째 필드에 각각 이름 붙여서 출력.
이렇게 출력하면 많은 데이터를 가시적으로 볼 수 있다.
awk -F: '{print "USERNAME: "$1,"SHELL: "$7}' passwd

aaa 계정을 생성하고 비밀번호를 잠궈보자.
passwd -l aaa

한번 로그인 들어갔다가 나온다.

정보를 보면 앞에 !! 라고 느낌표 두개 있는 부분이 패스워드 잠금됐다는 뜻이다.
cat /etc/shadow |grep 'aaa'

이런 계정 정보만 찾아보려면
~~~
cat /etc/shadow | grep 'sshd'
아까랑 달리 !! 뒤에 패스워드가 없다. → 비번 바뀐 적 없이 계정이 잠겨있다는 뜻이다.

계정 비밀번호 잠금 해제
passwd -u aaa
중요한 것은 프로세스 관리 프로그램을 보면서도 원하는 정보를 awk로 필터링 해서 알아낼 줄 알아야 한다.
df
메모지에 대한 사용률을 모니터링 하다가 90퍼센트를 넘기면 LVM을 하거나 조치를 취해야 한다.
Use%를 보고 위험도를 측정하여 관리해야 할 때 필터링을 해야한다.
top
실시간 프로세스 모니터링이다.
이를 필터링 해주고 가시적으로 그래프화 해주는 써드파티 툴이 많이 있다.
ps -ef
사용자 뿐만 아니라 시스템에 의해서도 실행되는 모든 프로세스(-e)를 출력하는 상태이다.
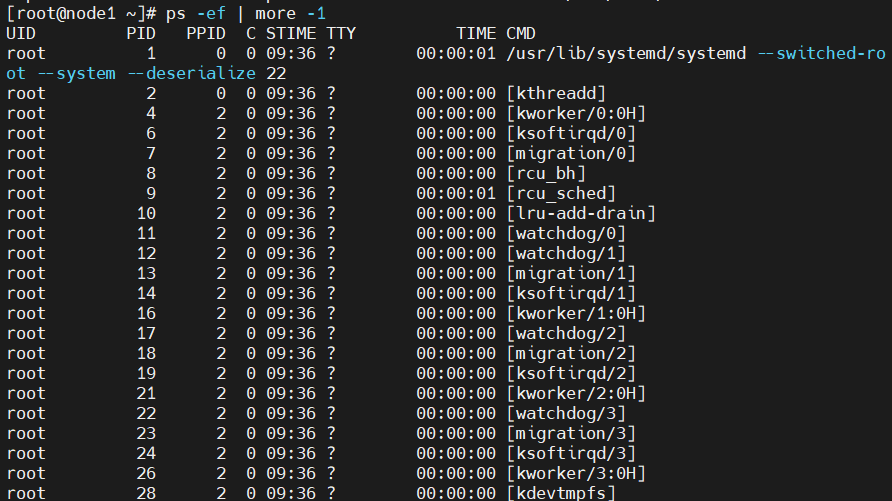
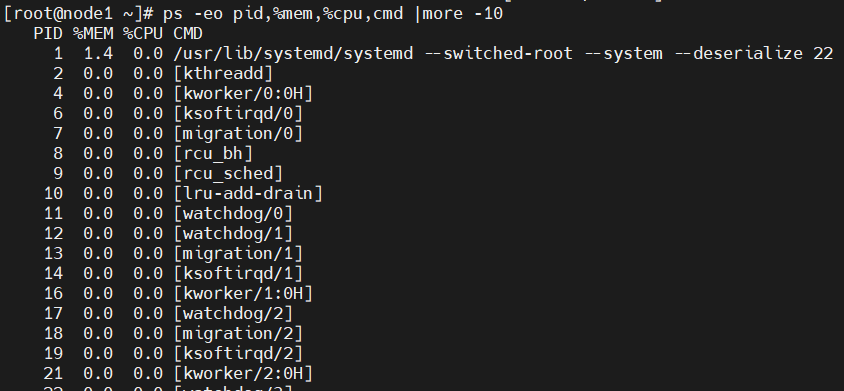
이 경우엔 -eo 옵션을 써서 보고싶은 정보만 필터링 해서 볼 수 있다.
특정 필드만 선택(-o)하여 보는 옵션
ps -eo pid,%mem,%cpu,cmd |more -10
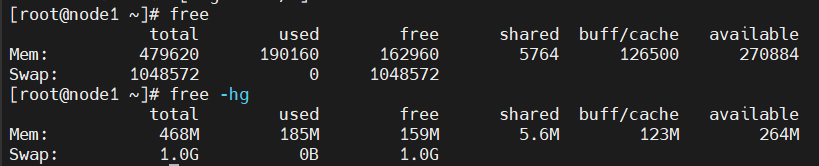
free -hg
db는 메모리 공간을 크게 만드는게 중요하다.
데이터 베이스용 가상머신을 만들거면 메모리의 양을 좀 여유있게 써야 한다.
프리스페이스로인해 버벅거리는걸 막아야하기때문이다.
렌더링 하려면 cpu를 여유 있게 가져가야한다.
ftp 서버라면 랜카드 버퍼가 좋아야한다.
소프트웨어적 랜카드보다 하드웨어적 랜카드(칩셋 지원?)가 훨씬 좋기 때문.
여유공간 limit을 확인하자
피크여도 보통은 70% 언더에서만 놀 수 있도록 해야한다.
du
파일 단위로 디스크를 얼마나 쓰고있는지를 알려준다.
sysstat
yum install - sysstat
sar 라는 명령어를 쓸 수 있게 된다.
vmstat

uname

Process 관리 프로그램
서드파티 프로그램중 잘 만든 것들을 소개해 본다.
yum -y install epel-release
페도라에서 제공해주는 특정 리포지토리를 추가해준다.
추가해 놓는 것이 좋다.
yum -y install htop atop nmon glances
process 테스트용 덤프 ps
yes 프로세스를 쓰면 cpu를 단숨에 풀로 쓰게 만든다.
테스트 할때 주로 사용
yes > /dev/null &
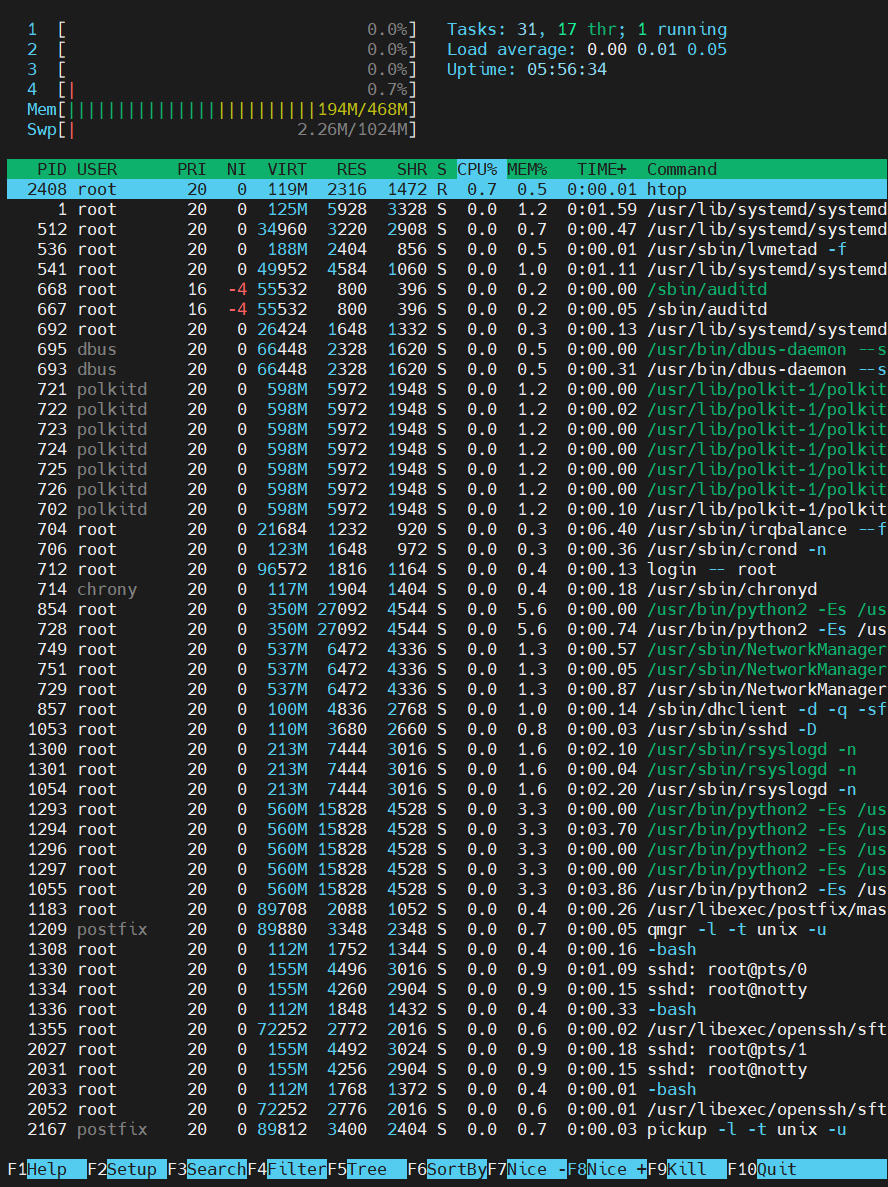
htop
프로세스를 관리하는 프로그램이다. TOP보단 보기 좋게 나와준다.
마우스를 지원하기 때문에 하단의 버튼을 마우스로(!!!) 눌러서 kill 할 수도 있고 필터링 할 수도 있다.
atop
nmon
iostat
in output 통계를 내준다. 주로 읽기를 많이하는지 쓰기를 많이하는지 등을 통계내준다.
TCPdump
와이어샤크의 cui 버전이다.
yum install -y tcpdump
tcpdump -i ens33
아래와 같이 호스트네임으로 나타나는 부분을
tcpdump -i -n ens33
-n 옵션을 붙여서 IP 로 바꿔줄 수도 있다.
pstree
yum install -y pstree
프로세스를 부모-자식 트리 형태로 나타냄
watch uptime
프로세스의 업타임을 지속적으로 보여준다.
서버에서는 업타임이 중요하다.
왜냐면 껐다 켠적도 없는데 업타임이 변경되면 서버에 이상이 생긴것이기 때문.
5초 간격으로 모니터링
watch -d -n 5 ‘cat /proc/uptime’
iostat을 10초 간격으로 샘플링해서 모니터링
watch -n 10 iostat
'Linux' 카테고리의 다른 글
| ss (natstat) (0) | 2023.01.09 |
|---|---|
| rdate - 타임서버와 시간 동기화 (0) | 2022.12.22 |
| sed (스크립트) (0) | 2022.12.15 |
| egrep 정규표현식 (연습) (0) | 2022.12.14 |
| VMware 네트워크 새 세팅 (0) | 2022.12.13 |


